Unified. Resilient.
Ready.
Always-On. Always Protected.
Integrated Data Resiliency
Resilient by Design
Our platform integrates data protection at its core, not as
an add-on.
Real-Time Recovery
Workloads are safeguarded from drive, server, and user
failures instantly.
Inline Deduplication
Global deduplication reduces waste while maintaining peak
efficiency.
Always Available
Built to ensure operations keep running, no matter the
disruption.
Simplified Disaster Recovery
Encapsulated Environments
Entire data centers—including compute, storage, and
networking—move as one.
Seamless Replication
Easily replicate workloads for predictable, rapid recovery.
No Extra Layers
Eliminate the need for bolt-on tools and complex
integrations.
Recovery Without Complexity
Restore business continuity quickly and with confidence.
How it works
Frequently Asked Questions
Our ultraconverged design collapses compute, storage, and
networking into a single operating layer. Unlike legacy stacks
that rely on separate hypervisor, SAN, and SDN components,
everything here is integrated natively. This eliminates
inefficiencies, reduces overhead, and provides unified
visibility and control across the entire data center.
KorGrid's architecture is built entirely on NVMe storage from
end to end—no hybrid or spinning media tiers. Every node,
volume, and replication path leverages NVMe's parallel
throughput and ultra-low latency to deliver consistent,
high-performance I/O at scale.
Because the storage fabric is integrated directly with the hypervisor, it eliminates controller overhead and achieves full active-active utilization across nodes. Global, inline deduplication further enhances performance while dramatically reducing total capacity requirements.
Because the storage fabric is integrated directly with the hypervisor, it eliminates controller overhead and achieves full active-active utilization across nodes. Global, inline deduplication further enhances performance while dramatically reducing total capacity requirements.
The environment maintains continuous data protection across all
tiers. Each data block is written redundantly across multiple
drives and nodes, ensuring protection against hardware or
user-level failures. Automated failover instantly relocates
workloads when needed, maintaining uptime and integrity even
during component or server outages.
Our platform employs hypervisor-wide deduplication that operates
inline and globally across all nodes. Redundant data blocks are
identified before transmission, preventing unnecessary
replication across the network. This reduces CPU and network
load, delivering higher throughput and greater efficiency than
storage-only or post-process deduplication.
Our snapshots are designed for efficiency and scale. Snapshots
act as independent, space-efficient clones that can be created
and retained indefinitely without impacting performance. This
allows administrators to perform rapid rollbacks, long-term
retention, and test/dev cloning without the cascading
dependencies found in traditional snapshot systems.
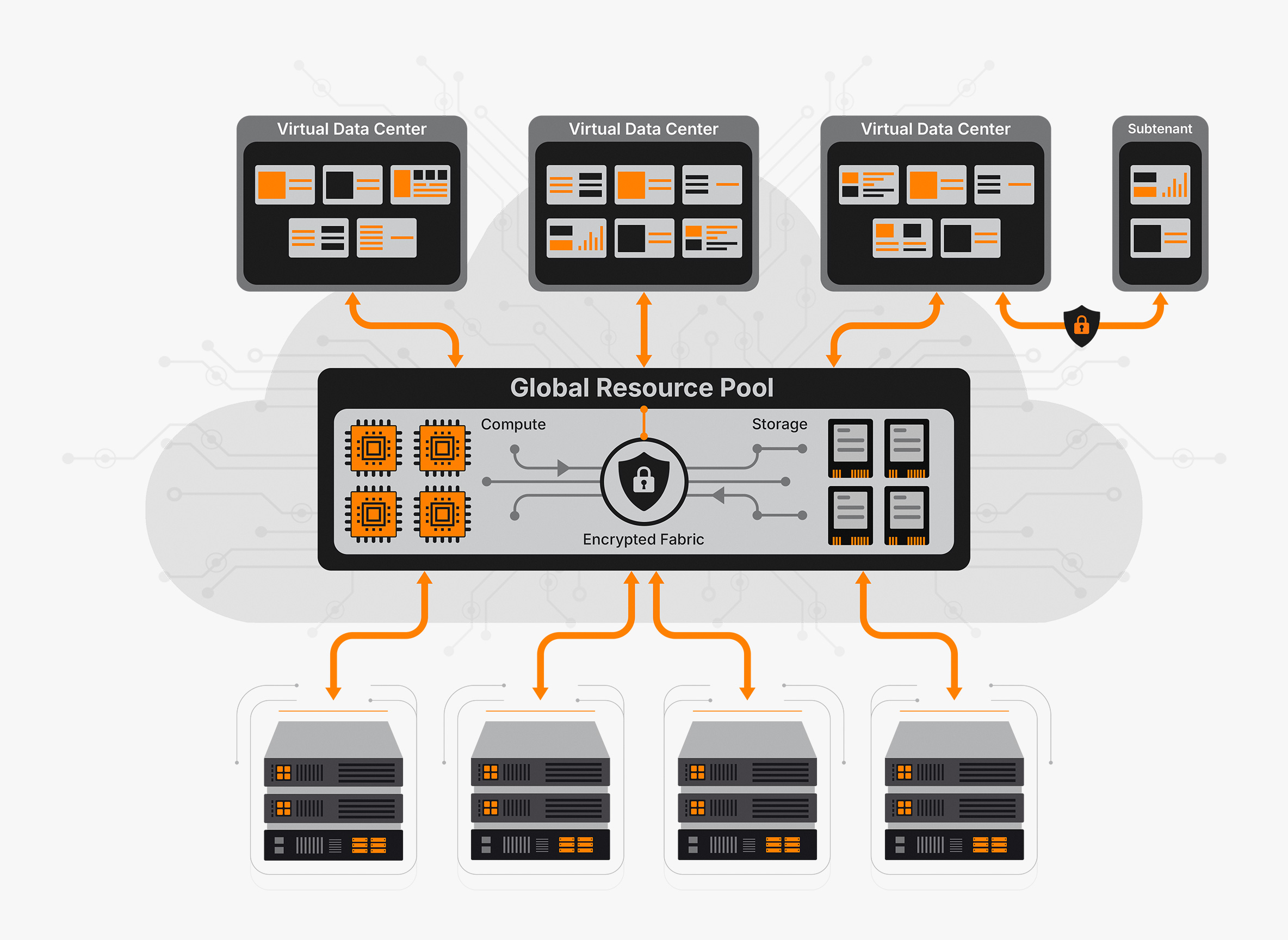
Compute, storage, and networking are encapsulated into Virtual
Data Centers (VDCs)—self-contained units that can easily be
replicated. This structure enables near-instant recovery.
Built-in replication, failover automation, and policy-based
recovery make DR testing and execution fast, consistent, and
reliable.
A native software-defined networking (SDN) layer provides
routing, firewalling, VPN, and segmentation without the need for
external SDN controllers or licenses. It supports BGP, OSPF,
IPSec, and WireGuard, delivering secure multi-site connectivity,
network isolation, and simplified automation directly within the
platform.
Virtual Data Centers (VDCs) provide complete tenant isolation within
shared physical infrastructure. Each VDC operates as an independent
environment—with its own compute, storage, and network
policies—ensuring security, performance consistency, and
compliance. This makes our platform ideal for MSPs, enterprises,
and organizations managing multiple teams or customers.